Managing and Tuning NetCrunch Alerts and Notifications
Understand the various settings in NetCrunch that control alerting and notifications. Learn how to effectively manage and tune alerting to achieve the desired level of notification. NetCrunch provides comprehensive monitoring across all critical aspects of your IT infrastructure. As a result, there are many elements that combine to dictate alerting and notification behavior. Managing the responses and level of interactivity, of your monitoring system, is critical to the perception of monitoring value. Too much alerting and the system goes ignored, while not enough notification leaves you surprised when issues occur. Provided is a guide for tuning NetCrunch to achieve your optimal alerting and notification levels. It is the intelligent combination of these techniques that provides you both the tuning feature set and flexibility to arrive at your organization's ideal alerting and notification level.
The techniques detailed in this article can be described in 4 broad categories for managing Alerts and Notifications:
- Managing Monitoring Scope by device inclusion or exclusion
- Managing Alerts by Action Script settings and Alert severity
- Managing Alerts by Policy membership or Node settings
- Managing Alerts by device Monitoring mode
Use Node Discovery Filters and Device Exclusions
The simplest method to manage device alerts is to consider whether a device is worth monitoring at all. There are several schools of thought here, but by simply asking whether or not a device is critical to an organization's Busines Continuity, you can determine its monitoring value. Eliminating low-value targets from your monitoring scope serves as the first and best method for eliminating undesired alerts and notifications. You don't have to monitor everything in order to monitor effectively. There are many reasons for a broad monitoring scope, but let the reasons drive your scope. A well-designed monitoring strategy that includes device selection as part of its criteria will serve you best in the long-run.
During initial setup, or when expanding your monitoring scope, you have the simple option to choose which devices will be added to NetCrunch via a device type filter. This setting is available in the IP Network Properties for each unique IP subnet configured in NetCrunch. These bulk device filters provide 3 options:
- All devices: all discovered IP devices via IP address scan
- Infrastructure devices only: switches, routers, servers, etc... (infrastructure critical)
- Only devices matching SNMP filter: device policy filter using SNMP meta-data
You can also specify IP ranges or specific IP addresses to be excluded, which eliminates undesirable devices from being discovered or added to the NetCrunch Atlas each time your auto-discovery routine is run.

Scan/Rescan Monitoring Dependencies
Once you have added all the necessary IP networks and have scanned your IT infrastructure, or if you add additional switches or routers with downstream devices, it is a best practice to rescan the Monitoring Dependencies of your NetCrunch Atlas to correctly identify device hierarchies and inter-dependencies. This will eliminate the occurrence of cascading alerts while providing correct monitoring statuses. Discovery of device dependencies in NetCrunch eliminates the need to manually describe how your devices are connected.

This feature requires Physical Segments to be enabled and takes into consideration both physical and virtual switch topologies. If a critical network device fails, all dependent and downstream devices will reflect the status of 'Down by Dependency', and the monitoring status of the parent device will reflect correctly as 'Down'. Alerts are suppressed for a device when a dependent node has caused the device outage. You will not receive alerts for devices that cannot be directly determined as down by NetCrunch... unless you change this behavior. It is best to leave this setting as default. This device setting becomes less important when switches are excluded from your monitoring scope.

Tune Action Scripts
NetCrunch uses the individual assignment of Action Scripts to Alerts, in Monitoring Packs and Sensors, to describe the desired event generation and notification behavior given a particular detection. Tuning your Alerting Scripts to include the correct notification settings starts with describing escalation behavior. 3 categories and 1 checkbox are used to accomplish this:
- Action to Run Immediately
- Action to Run After ...
- Action to Run on Alert Close
- Checkbox: Until alert cleared, run last action every...
Each Action Script element includes important settings and execution parameters that allow the user to describe appropriate Restrictions in order to manage a particular alerting behavior :
- Time - provides for time-based exclusions
- Atlas View - focuses alerting to a specific group of devices
- Severity - filters the alert behavior based on the severity
- Organization - filters the alert based on Organization

A common mistake in customizing an Alerting Script is omitting Severity. NetCrunch, by default, provides notification behaviors on alerts carrying the Critical severity. All other alerts (Warning, Minor, Informational) are logged in the Event Log tab of the appropriate Atlas View. Be sure to add an Immediate Alert to the default Action Script if you would like your initial notification to be at issue onset. By default, NetCrunch will escalate to notification after 5 minutes.
Disable or Pause Monitoring for IP Networks of Targeted devices
In particular scenarios, you may choose to disable or pause device monitoring on a single device or a particular IP Network to eliminate unnecessary alerts during a maintenance window. This effectively pauses NetCrunch's monitoring in a focused manner, and as a result, will detune the associated alerting and notification behavior. In the case of wide-reaching maintenance windows, you can also leverage monitoring dependencies to disable monitoring on key network devices, which will have the effect of eliminating the associated cascading alerts that would be otherwise generated outside of the 'down-by-dependency' relationship.

Tune Device Service Monitoring
A fundamental tenant of monitoring is NetCrunch's ability to handshake and validate device services. This is determined by your Automatically DIscovered Services settings located in Tools > Options > Monitoring > Auto Discovered Services. Aligning with this ability is the default setting that generates a Critical alert when a discovered service goes down. It is possible that you might receive notifications on service outages on non-critical devices. For example, if you are monitoring Workstations, and a developer has a local instance of SQL Server. This approach can be used to manage unwanted alerting on a case-by-case basis by eliminating unnecessary service monitoring on non-critical devices. These adjustments can be made in the Node Settings of the target device.

Tune Monitoring Pack Policies
In the case where NetCrunch is providing unwanted alerts, you can alter automatic monitoring packs by adjusting their association policy or filter criteria. This allows you to affect a broad range of devices and represents the easiest method for affecting a large number of devices of a certain type. An example of this scenario is when you wish to monitor workstations when they are active, and not receive alerts when the user leaves for the day. This can be accomplished by providing additional filter criteria on the Node Status and Service Status Monitoring packs. NetCrunch offers a broad array of meta-data fields from which device exclusions can be described, giving monitoring packs the correct membership description for associating with devices.

Additionally, individual alerts within a monitoring pack can be modified to reduce undesired notifications. This strategy is ideal when the filter policy correctly selects devices. Alert elements of a monitoring pack that can be changed are:
- Alert Severity - accomplished by editing the Alert rule
- Alert Trigger options - includes sampling and schedule logic
- Alert Action Script - selecting Write-to-Log, or an Alerting script that does not include notification
- Disable the Alert - turns off both polling of metric and Alert rule enforcement
If you intend to make changes to automatic monitoring packs, it is considered a best practice to first duplicate the monitoring pack, then disable the original before making changes to the Alert/Collection strategy. As a courtesy to your modifications, NetCrunch will not update modified automatic monitoring packs, which would preclude you from future changes to default strategies in later editions. You will always receive new monitoring packs when you upgrade. As a simple rule, duplicate then deactivate,
Device Level Alert Exceptions from Event Log
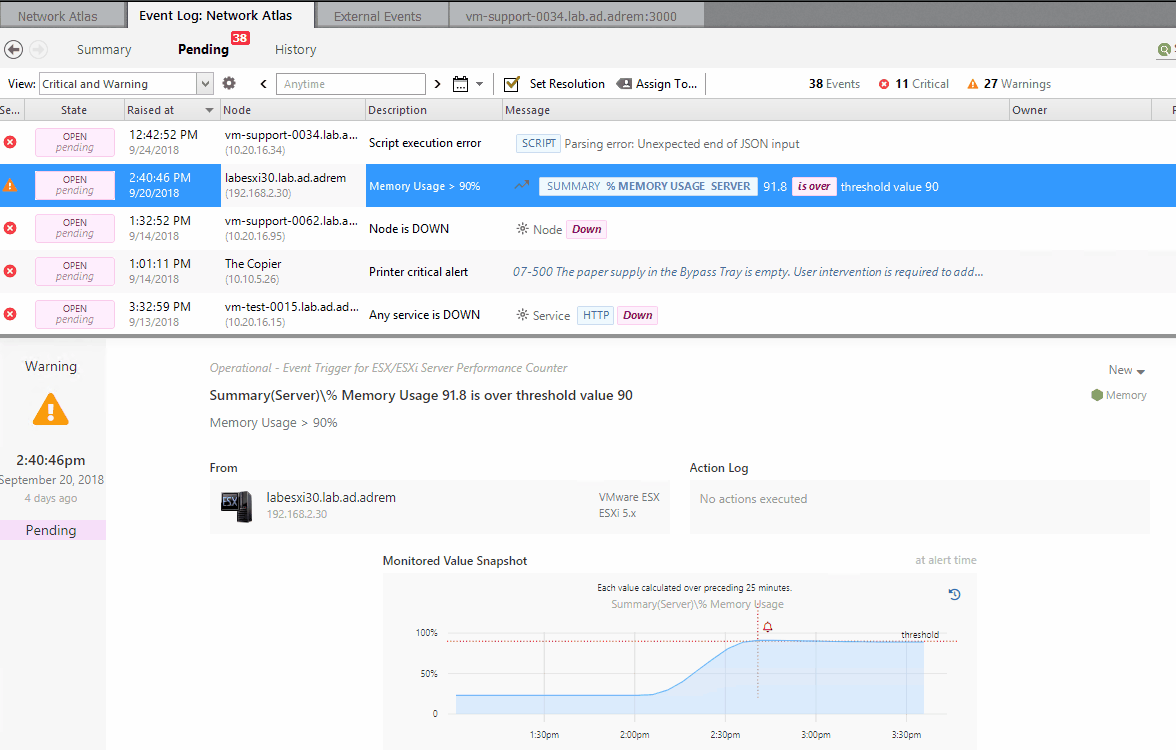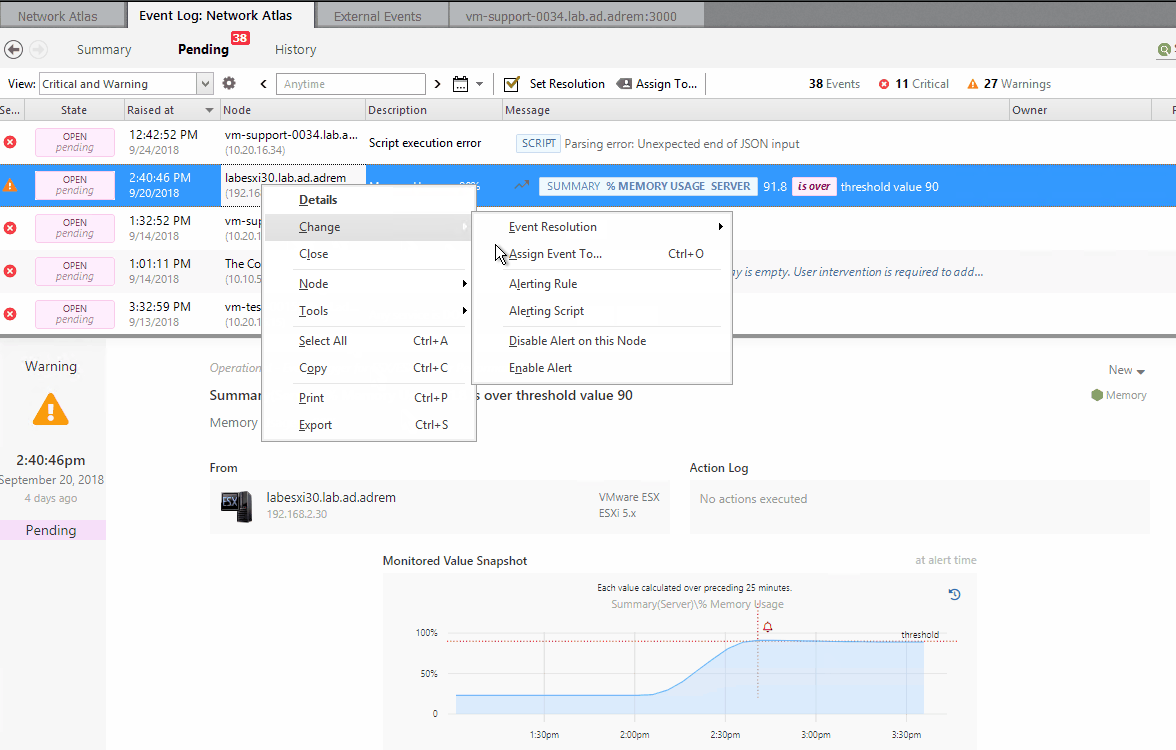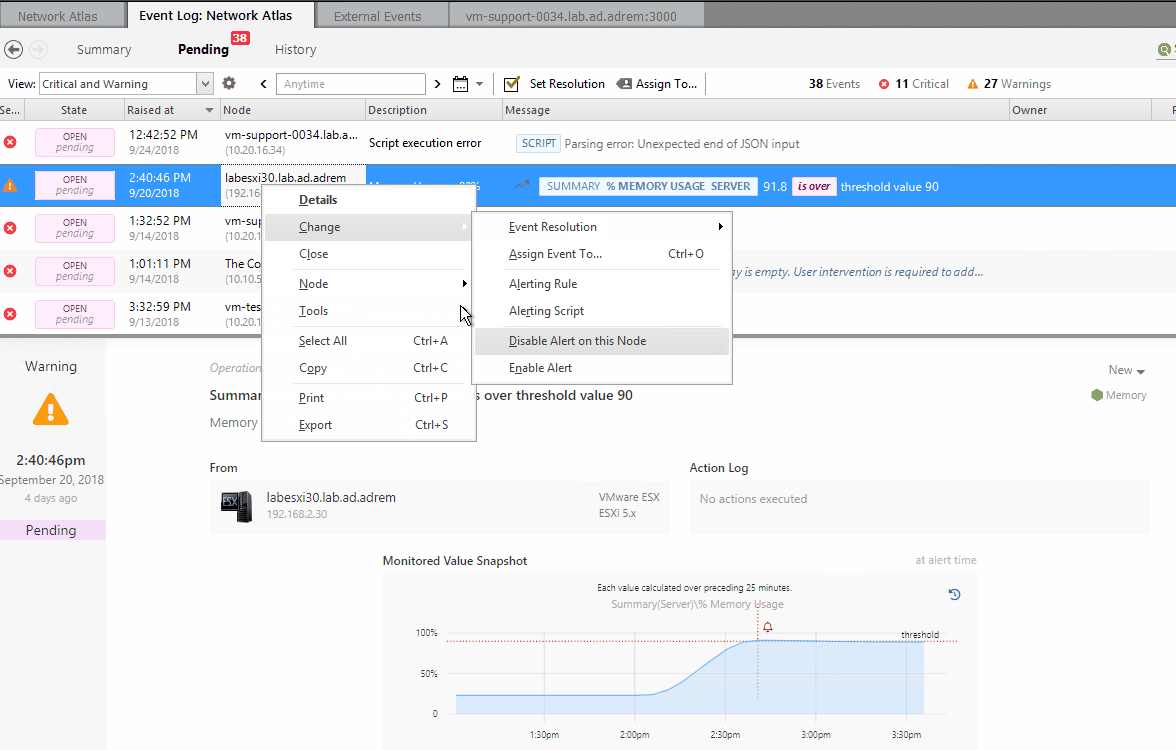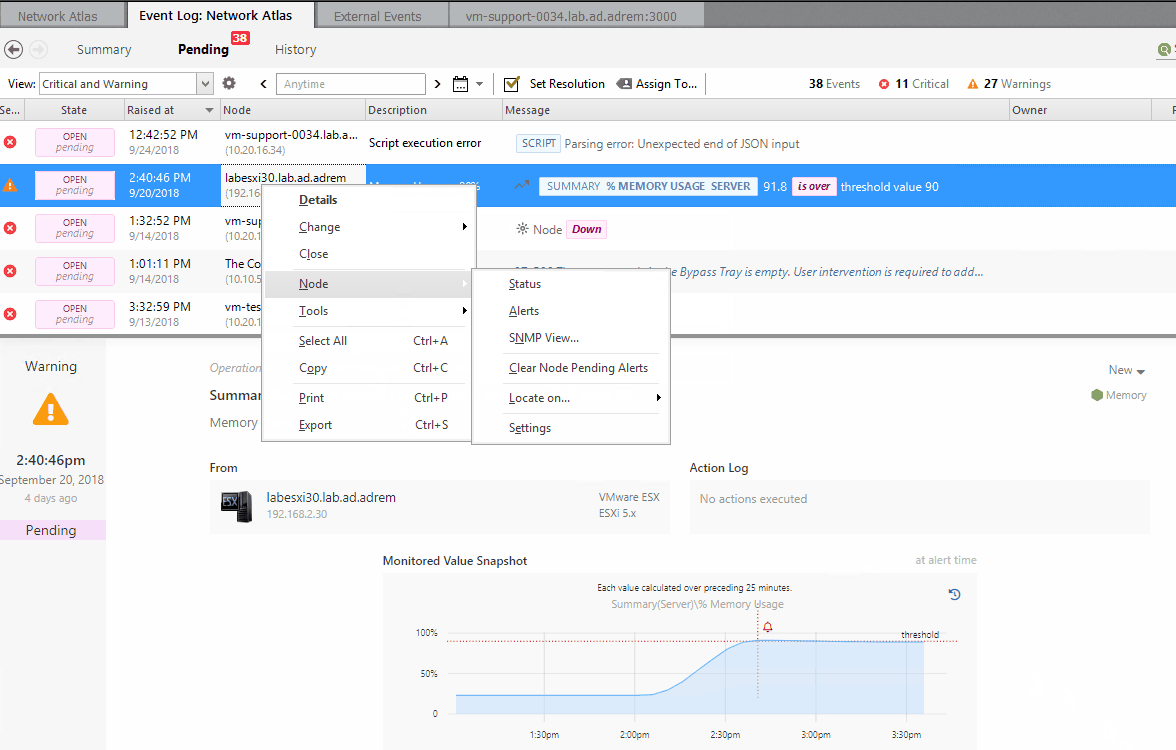
Another method for tuning Alerts and Notifications is available in the Event Log of any view that includes the Alert in question. Additional tools are provided for managing alerts by selecting the Alert and choosing from the following options available in the right-click menu:
-
Change
- Alerting Rule - direct access to the rule and trigger logic
- Alerting Script - direct access to Alerting script
- Disable Alert on this Node - creates device level exception to single Alert
-
Node
- Clear Node Pending Alerts - clears and pending alerts for the device
Use Collections for Alert-free metrics
NetCrunch includes 2 methods for introducing monitored metrics into the Trend database: Alerts and Collections. By detuning Alerts, it is conceivable that otherwise useful metrics have been eliminated from NetCrunch. Collections provide the necessary mechanism for polling and aggregating device data, without assigning alerting logic, and are designated at the Monitoring Pack or device Node Settings level. Metrics described in Collections are available in the Device Status > Performance tab, just like metrics designated in Alerts.

Use Simplified Monitoring on Non-Critical devices
You have 2 methods for monitoring devices in NetCrunch.
- Standard Monitoring - full monitoring, supporting all NetCrunch features, supports alerts and notifications
- Simplified Monitoring - services only monitoring, no alerts or notifications
By selecting Simplified Monitoring, a device's discovered services are monitored, but no other polling for counters or metrics occurs. This is an ideal setting for the following types of devices:
- Polling permissions unavailable, but status/availability important
- Low priority devices
- Unmanaged devices
By switching to simplified monitoring on devices that NetCrunch lacks permissions, you can eliminate the excessive logging that will occur with incorrect user/password challenges.

- [08.02.2019]SNMP monitoring features in NetCrunch
There is a lot of the ways of how we can monitor the condition, performance and availability of the devices with available SNMP service running on them. Learn how to gather the counters and states from various devices with the tools available in the NetCrunch.
- [06.12.2018]Alert Escalation Scripts
Define and customize how NetCrunch generates events, triggers alerts, and executes actions based on monitoring detections, metrics, and device status.
- [06.07.2018]Analyze Windows failed login events with a custom log view
Use NetCrunch to monitor and display failed logon activity on all Windows machines in your network by monitoring Windows Event Log.
- [12.02.2018]Process Monitoring with NetCrunch WMI Sensors.
Learn how to configure a node-specific WMI Object sensor to monitor a specific Windows process and generate an event when the process is restarted. This sensor-based monitoring strategy leverages the uniqueness of PID, against the generic name of a process.