Optimizing SNMP Monitoring in NetCrunch
This article will explain reasons for most common SNMP monitoring problems, describing ways to fine-tune SNMP monitoring settings in NetCrunch. Learn how to monitor without stressing your SNMP device.
The main purpose of SNMP devices (especially routers and switches) is to run your network, so they prioritize their resources to do their job, and only small percentage of their resources can handle secondary tasks, like for example responding to monitoring requests.
This is why it is very important to find the right balance when tracking the device key performance metrics so the monitoring would not negatively affect its performance. Modern routers and switches are often designed to ignore monitoring requests if they are received too often or when are overloaded (requests wait for certain time to be processed and then discarded).
Symptoms of SNMP device overloading with monitoring
- A large number of timeout alerts on the device
- A high number of false-positive "node is down" reporting
- Processor Utilization on the device is high
- SNMP service is down very often
Examples of the behavior of significantly utilized SNMP on the device.
See how you can identify SNMP monitoring problems in NetCrunch - and how to fix them.
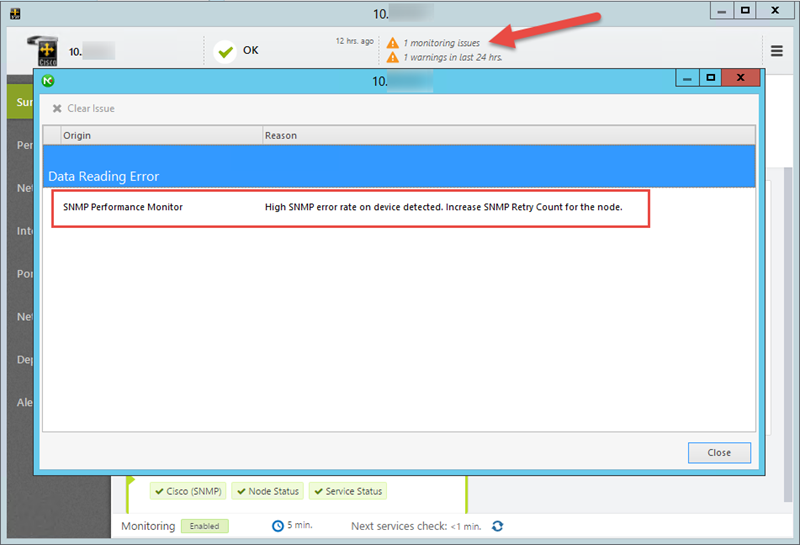
As presented above - NetCrunch generates a monitoring issue on the SNMP device, this is one of the first symptoms that the device is pooled for data too often, and due to heavy load, it might not be able to respond to every SNMP request.
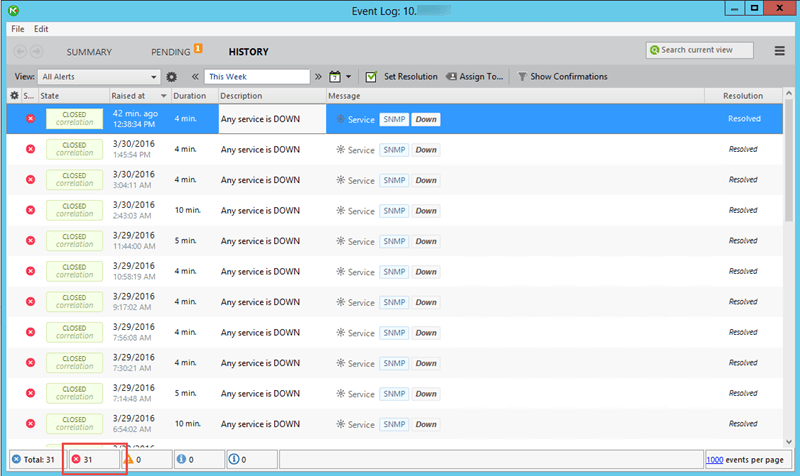
History view shows a large number (31) of "SNMP is down" alerts generated by one device during a single week.
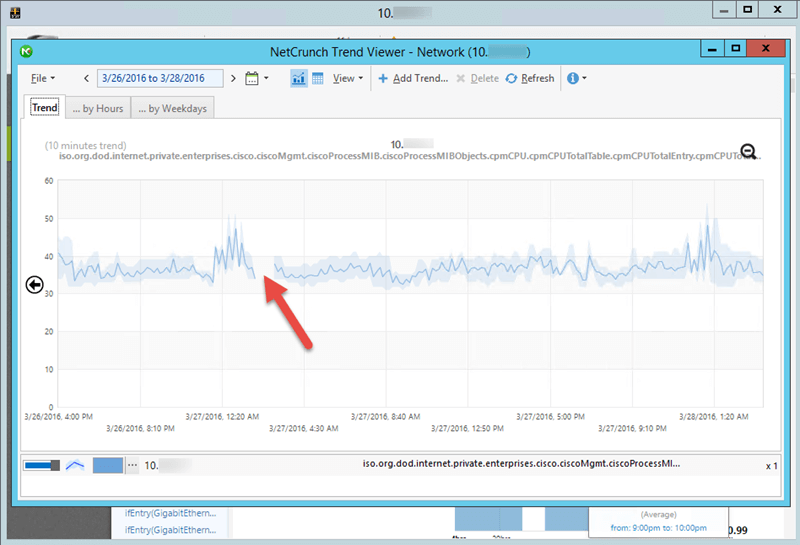
The screenshot above shows the trend of processor utilization on the SNMP device - a gap in trend represents a time when the device did not respond to NetCrunch requests. You can also notice that the processor utilization before the gap was really high on this device.
SNMP monitoring - finetuning tips
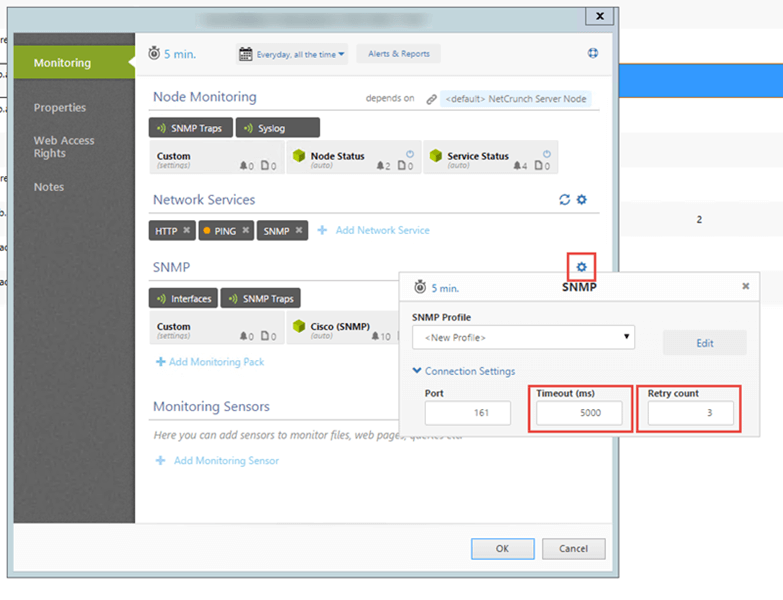
If the SNMP device fails to respond to NetCrunch requests, the first thing to change is to increase Retry Count and Timeout of the SNMP Monitor. This setting will allow NetCrunch to have more patience for failed or delayed responses.
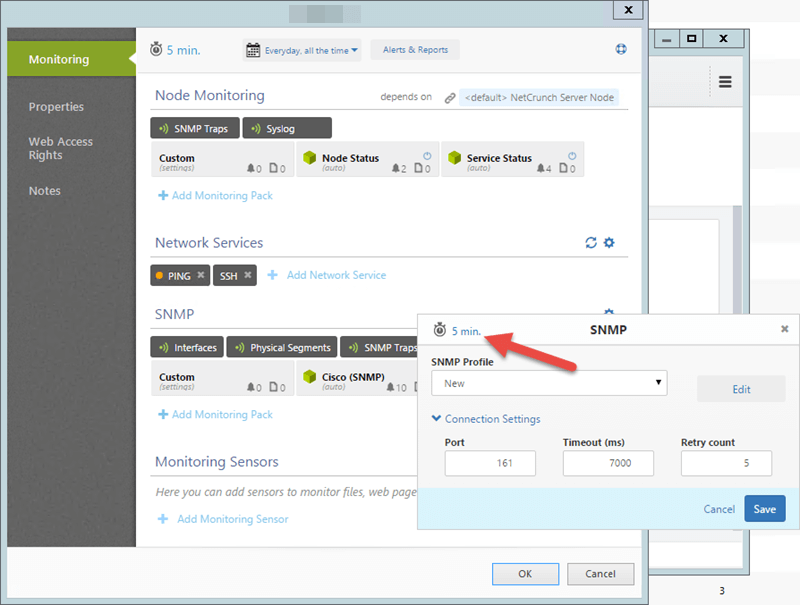
If the SNMP device is busy, we also recommend to increase monitoring time. NetCrunch will delay sending repeated requests so that device has more time to process the first request.
Last but not least - avoid using multiple Network Monitoring Systems to monitor the same device. Multiple similar requests sent to the device at the same time may cause undesired resource utilization. In the worst case, it may even hang a device, treating the monitoring traffic as an attempted DoS attack.
- [25.06.2018]How to start monitoring of new SNMP device with NetCrunch
Is your device monitorable? Read the article to learn how to approach configuring monitoring for a new device.
- [05.04.2017] Using NetCrunch to track Port Security status of Cisco switches.
Cisco port security is a great feature to make your network safer. Learn how to configure NetCrunch to display the status of Cisco Port Security on the switch interfaces.
- [21.04.2016] Monitoring External Events in NetCrunch
Using multiple tools to catch every SNMP trap or SYSLOG message might be hard. NetCrunch simplifies this task with the External Events window and lets you fine-tune your log and SNMP monitoring: